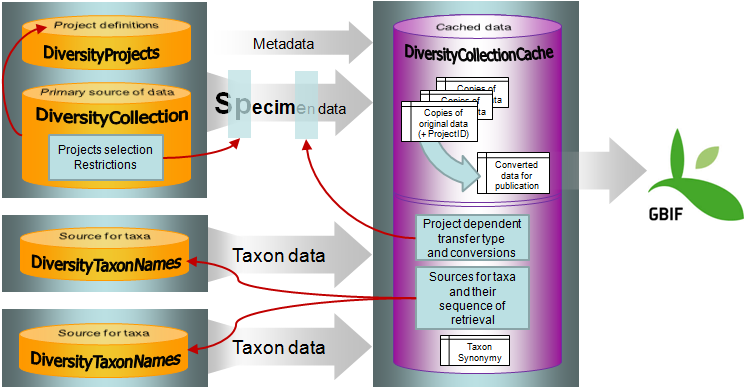
The cache databases for
DiversityCollection are
designed as sources for preformated data for publication in e.g.
public user
portals like GBIF. There may
be several cache
databases which can be located on several servers. The
restrictions of the
published data are defined in the main database via projects, data
withholding
and embargos. The
publication of the data
is allways related to a project, defined in DiversityProjects,
holding the
metadata that will be transfered into the cache database.
Therefore every dataset
copied from the source into the cache database contains a
reference to the
project (ProjectID).
The publication of the data includes several steps:
In Addition to the data transfered from DiversityCollection, the
data for the taxonomy has to be transfered from the relevant sources.
The links to these sources and the project dependent retrieval are
stored in the
cache database.
The image below gives an overview for the process described above.
To configure your cache
databases, choose Administration
->
 Cache database from
the menu. A window will open as shown below.
Cache database from
the menu. A window will open as shown below.
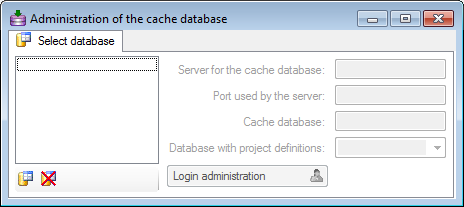
If no cache database has been
defined so far, use
the
button to create a
new cache
database. You have to be a System administrator to be able to create
a cache
database. You will be asked
for the server, the port used by the server, the
directory of the database files, the
name of the
new cache database and finally the name of the projects database
where the
metadata of the projects transfered into the cache database are
stored.
To delete a once created cache
database, use the
 button.
button.

After the new cache database has
been created or if
you select an outdated cache database, a button
Update database
will appear,
instructing you to
run updates for the cache database. Click on the button to open
a window
as shown below.
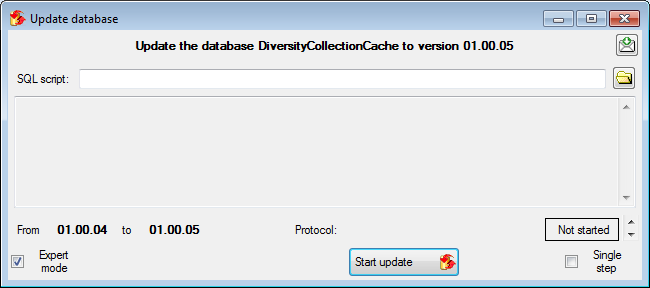
All update scripts for the database
will be listed.
Click on the
Start update
button to update
the database to
the current version.

To handle the data for the cache
database a user
needs access to the data on the source database, the
cache database, the project
database and the taxon databases. To
administrate
the users that can transfer data into the cache database use the
button
Login administration.
For details see
the chapter Login
administration.
Data transfer to the cache database
is linked to
projects
. To add a project of
which the data should be transfered into the cache
database click on the
 button. For every project
that should be transferred you
have several options for configuration:
button. For every project
that should be transferred you
have several options for configuration:
Data types handle the data for the cache database. A user
needs access to the data in the source database, the
cache database, the project
database and the taxon databases. To
administrate
the users who can transfer data into the cache database, use the
button
Login administration.
For details see
the chapter Login
administration.
 , Material categories
, Material categories
 , Localisation
systems
, Localisation
systems
 or Images
or Images

To restrict the Taxonomic groups, Material catagories, Localisation systems or Images that are transferred to the cache database choose the corresponding options and select those that should be transferred into the cache database in the tab pages that are added.
To reduce the precision of the coordinates of the localisation systems transferred to the cache database you can check the corresponding option and determine the number of digits after the decimal point.
The collection data may be linked to sources holding taxonomic information (DiversityTaxonNames). To provide this information add all sources used in your collection data and transfer the corresponding data into the cache database. The data in the taxonomic sources are organized by projects, thus, you need to provide the sequence of the projects that should be imported into the cache database for every source. A name will be imported only once. This means that the name with synonymy to the first imported project will be imported, all following data with this name will be ignored.