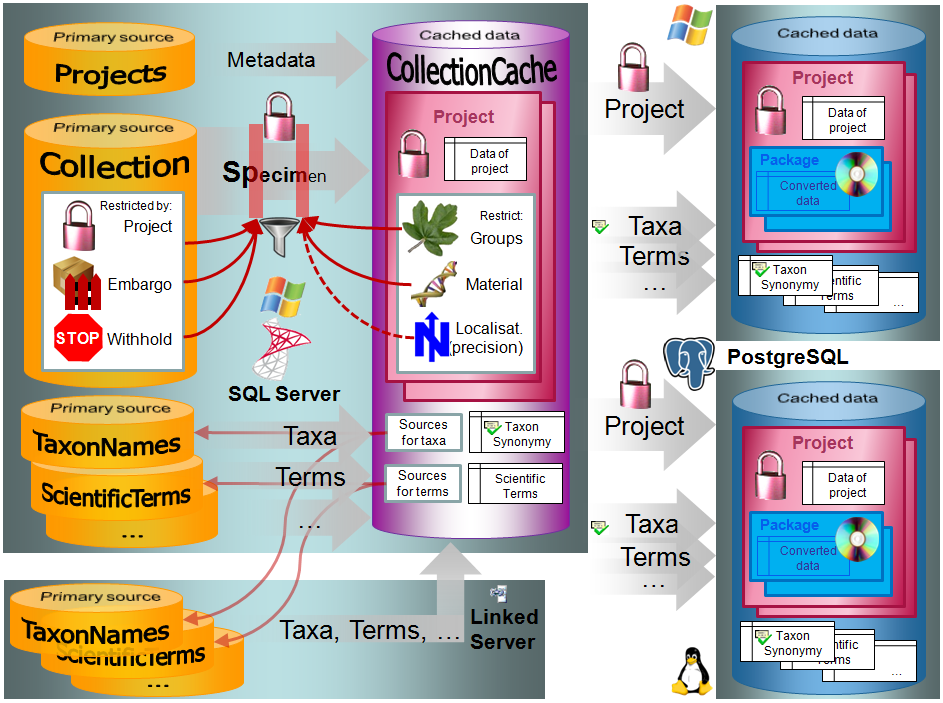
Cache
database
The cache databases for
DiversityCollection are
designed as sources for preformatted data for publication in e.g.
public user
portals like GBIF. For an introduction see a short
tutorial

 . The cache
database by default has a name corresponding to the main source database, e.g.
DiversityCollectionCache and is located on the same server and by itself is the
source for the data in
. The cache
database by default has a name corresponding to the main source database, e.g.
DiversityCollectionCache and is located on the same server and by itself is the
source for the data in
 Postgres (Version 9.4 or above) cache databases located on any
Windows or Linux server (see image
below). An overview for the basic steps is provided in chapter Basic steps for publication of data via the cache database.
Postgres (Version 9.4 or above) cache databases located on any
Windows or Linux server (see image
below). An overview for the basic steps is provided in chapter Basic steps for publication of data via the cache database.
Generating the cache
database

To create a cache database you need to be a system
administrator (s. Login administration). The
creation of the cache database is described in the chapter Creation of the cache
database.
Projects
The
publication and transfer of the data
is always related to a
project. Every project has its own
database schema containing the data tables etc. The metadata are defined via
settings in a
DiversityProjects database. The Projects module provides a stable identifier for
each Project. The basic address has to be set in the Project module (choose
Administration - Stable identifier ... in the menu). Please turn to the module DiverisityProjects for
further information. The metadata will be transferred into a table in the cache
database. For further details see chapter Projects in the cache database.
Scientific terms, agent, taxonomy and other sources

As well as data from DiversityCollection, data
from other modules like DiversityScientificTerms containing terms, DiversityTaxonNames containing the
taxonomy, including accepted names and synonyms are transferred into the cache database and may be retrieved from the local server or a
 linked server.
The data of these sources are stored and transferred independent from the
project data. For further details see the chapters about agents, terms and taxonomy.
linked server.
The data of these sources are stored and transferred independent from the
project data. For further details see the chapters about agents, terms and taxonomy.